爬虫引擎
![]()
HAWK-X——下一代智能爬虫引擎
介绍
HAWK-X 是一款基于 事件(Event)驱动的 Web 2.0 启发式浏览器爬虫。HAWK,中文意思 “鹰”,取名 HAWK 寓意着,像鹰一样拥有锐利的眼睛,旨在更全面全能的发现网站中的链接;——X:代表该工具的代号,也代表无限支持的业务场景。Event 事件驱动 指的是,整个工具的研发过程中 80% 的核心功能都是由事件驱动的,事件驱动包含:浏览器事件、页面事件、DOM 事件。
HAWK-X 采用Golang开发,拥有极简且高性能的页面调度引擎。它采用高效的 human-like 页面交互访问算法,能够智能模拟人的点击行为、输入等操作,智能停止、返回、继续深入点击。因此,它可以智能爬取Web 2.0(前后端分离技术)网站和其他普通网站。
快速使用
在命令行终端中执行以下命令:
ez crawler -u https://www.target.com
关键特性
极简的页面调度引擎,简洁高效。
支持分布式能力:
联合自研的 RBI 技术的分布式插件 HAWK-Remote 能够实现:
a. 分布式部署
b. 分布式任务调用
c. 分布式远程无界面可视化实时操作登录
支持多种登录方式:不仅仅支持传统的自定义 Cookie,header还支持自定义 localStorage,分布式远程/本地无界面实时可视化操作登录(SSO,SDP等),业内登录认证方式最全的网络安全爬虫
支持多种文件类型解析爬取,JSON,OpenAPI 配置文件,XML,robots.txt等
业界自研最完整的请求头抓取算法,能够有效抓取 JS 计算增加的额外的请求头
自研页面稳态监控算法,智能监控判断页面加载渲染情况,进行自适应等待,极大地提高前后端分离站点的爬取成功率
丰富的自定义可控过双通道过滤去重机制,按照自定义粒度按需减少不必要的资源消耗,同时支持请求状态码输出、过滤
支持浏览器协议级别的危险操作识别防护,即使有意触发也会被拦截,助力无损扫描更近一步
丰富的自定义配置项:贯穿整个任务的生命周期,包含浏览器配置、任务配置等。
可以智能爬取 Web 2.0 网站和普通网站,模拟人的行为进行点击输入等操作时,能够做到智能停止、返回、继续深入点击等,助力漏洞扫描更快一步。智能化的表单填充功能,智能识别表单数据规范,模拟填充符合表单规范的数据,请求成功率更上一层楼。
支持丰富的结果输出和推送:不仅仅支持本地 .txt .json(完整请求)文件输出,还支持非流量清洗和流量清洗的被动结果推送,是支持被动扫描工具或者产品的流量之源。
配置项介绍
HAWK-X 的配置主要分为两部分:CLI 和 config.yaml。
CLI 可配置项
在命令行终端中使用参数 crawler -h 可查看所有可使用命令行参数:
--text-output 输出简单的结果请求。例如:
[GET] https://example.comuseage:
ez crawler -u https://www.target.com --text-output ./result.txt
--json-output: 输出完整的请求 JSON 文件 。
content:
- Method:请求方式
- URL:请求地址
- Headers:请求头
- StatusCode:响应状态码
- Body:请求体,默认以 base64 编码的字符串
useage:
ez crawler -u https://www.target.com --json-output ./result.json
--push-proxy 将清洗后的流量结果推送至代理地址,一般用于支持被动扫描的工具,此处配置被动代理地址
useage:
./hawkx -t https://example.com --push-proxy https://10.7.26.144:8808
--no-banner 禁用输出banner
--disable-headless 禁用无头模式,整个任务的爬取过程中会弹出浏览器窗口,可实时观看到爬取过程。
useage:
ez crawler -u https://www.target.com --disable-headless
--wait-login 用于手动登录操作。此命令行会禁用掉无头模式,在执行爬取任务之前会弹出一个浏览器窗口,用于手动登录操作。确保登录成功之后,在命令行终端内按下回车键,即可继续爬取。还可以和分布式插件 HAWK-Remote 进行联动,在服务器环境下实现无头模式下进行远程可视化调用登录爬取。
useage:

ez crawler -u https://www.target.com--wait-login
配置文件可配置项
CLI 只是配置文件 HAWK-X_config.yaml 的一个 ShortCut,更多的配置可以在配置文件中进行配置。
chrome_path: ""
no_sandbox: true
leak_less: true
disable_headless: false
disable_images: true
proxy: "http://10.65.199.144:8010"
running_chrome:
enable: false
ip: 127.0.0.1
port: 0
hawk_remote:
enable: false
browser_alias: bugfly
HAWKRemote_address: http://127.0.0.1:7317
form_fill: true
chrome_temp_dir: ./chrome_temp
headers:
- domain: '*'
headers: {}
user_agent:
local_storage: {}
session_storage: {}
max_run_time: -1
max_depth: 10
navigate_timeout: 10
load_timeout: 10
max_page_concurrent: 1
max_page_count: 1000
max_interactive: 1000
scan_scope:
scan_scope: 1
domain_exclude: []
domain_include: []
stable_monitor:
stable_timeout: 10
stable_degree: 0
monitor_duration: 800
page_analyze_timeout: 100
new_task_filter_config:
disallow_status_code:
- 404
- 601
- 0
disallow_suffix: []
danger_fields: []
results_filter_config:
disallow_status_code:
- 404
- 601
- 0
disallow_suffix:
- .js
- .jsx
- .vue
- .ng
- .jsx
- .tsx
danger_fields: []
deduplication_level: 3
logger_config:
logger_level: info
logger_file_name: ./log/HAWK-X_Crawler.log
logger_output_level: []
logger_file_max_size: 50
logger_file_max_backups: 5
logger_file_max_age: 30
logger_prefix: ""
浏览器相关配置
chrome_path
- des:chrome 二进制文件路径,未指定时会从当前机器环境自动寻找
- useage:
C:\Program Files\Google\Chrome\Application\chrome.exe
disable_headless
- des:禁用无头模式,整个任务的爬取过程中会弹出浏览器窗口,可实时观看到爬取过程
- usegae:
true
disable_images
- des:是否启用图片显示,使用
--wait-login参数时,建议不要开启,可能造成图形验证码不能显示 - useage:
true
- des:是否启用图片显示,使用
proxy
- des:chrome 自身代理配置(此配置流量未经清洗)
- useage:
https://10.65.7.110:8090
no_sandbox
- des:是否开启sandbox;为 false 时默认开启沙箱,但在容器中会关闭沙箱。为true时禁用沙箱
- useage:
true
leakless
- des:实验性功能,防止内存泄露,可能造成卡住的现象,在 Windows 环境下建议关闭
- useage:
false
hawk_remote
- des:分布式能力配置,可以联动分布式插件HAWK-Remote,实现分布式部署、分布式调用爬取、分布式服务器环境下无头模式可视化操作登录。仅提供给相关商业产品,如:RSAS/WVSS/DSIT/EZ 商业版,暂未对社区开放
- useage:
- enbale 是否启用 HAWK-Remote
false - browser_alias 用于指定当前爬虫任务所启用的浏览器实例名称,只要符合编程语言的命名规范即可:
bugfly - HAWKRemote_address HAWK-Remote 分布式插件地址
http://10.65.3.110:8990
- enbale 是否启用 HAWK-Remote
running_chrome
- des:接管已经存在的浏览器环境
- usage:
- enable 是否启用
running模式的的浏览器 - ip 浏览器所监听的 IP 地址
- port 浏览器所监听的端口
- enable 是否启用
chrome_temp_dir
- des:浏览器临时文件存放路径,默认为当前路径下的
./chrome_temp文件夹 - useage:
./chrome_temp
- des:浏览器临时文件存放路径,默认为当前路径下的
任务相关配置
max_run_time
des:任务运行的最大时长,到达最大运行时长后自动结束爬虫任务,单位:min
useage:
-1-1:表示不限制运行时长
max_depth
- des:爬取的最大深度
- useage:
10
headers
- des:自定义请求头
- useage:
- domain:
'*'生效的域名,此处的配置一定要遵从浏览器-->开发者工具-->应用程序-->Cookie 里面的 Domain 字段进行配置否则不容易登录成功 - headers:
{}
- domain:
local_storage
des:自定义 LocalStorage 登录
useage:
local_storage:
token: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJVVUlEIjoiMDJkNTAxNTUtNDgyOS00ODlmLTg4NDMtMzc2Y2UwYWM0ZTNjIiwiSUQiOjEsIlVzZXJuYW1lIjoiYWRtaW4iLCJOaWNrTmFtZSI6Ik1yLuWlh-a3vCIsIkF1dGhvcml0eUlkIjo4ODgsIkJ1ZmZlclRpbWUiOjg2NDAwLCJleHAiOjE2Nzg2MTQ5MzUsImlzcyI6InFtUGx1cyIsIm5iZiI6MTY3ODAwOTEzNX0.Q0SXBYEvjzfM__ZS4djiUF9rOipQiguil8Jmn2B-DNA
session_storage
des:自定义 SessionStorage 登录
useage:
session_storage:
login_status: true
navigate_timeout
- des:访问超时时间,单位:s
- useage:
10
load_timeout
- des:加载超时时间,单位:s
- useage:
10
max_page_concurrent
- des:最大页面并发(不大于50)
- useage:
5
max_page_count
- des:总共允许访问的页面数量,
-1表示不限制 - useage:
1000
- des:总共允许访问的页面数量,
max_interactive
- des:单个页面最大交互次数
- useage:
1000
scan_scope:
des:扫描范围配置。1.全域扫描目标域名及其子域名都会进行扫描;2.目标域及其子路径扫描;3.当前域;4.目标URL。当为 2 范围时有着严格的限制概念:
target:https://127.0.0.1/subpath/xxx当发现https://127.0.0.1/subpath时,就会被判断为超出爬取范围被丢掉。useage:
scan-scope:
2domain-exclude:
[]全域扫描时,域名黑名单domain-include:
[]全域扫描时,域名白名单
stable_monitor:
- des:【页面稳态监控算法的实现】,用于智能判断页面加载渲染情况
- useage:
- stable_timeout:
10整体监控最大超时时间:10s - stable_degree:
0页面最大平稳度,取值范围 [0,1.0],取值越小越接近0,页面等待渲染越完整 - monitor_duration:
800监控平稳度的时间间隔,单位:ms
- stable_timeout:
page_analyze_timeout
- des:页面分析最大时间限制,单位:s
- useage:
300
form_fill
- des:是否开启智能表单填充
- useage:
true
new_task_filter_config:
- des:Task 通道过滤配置
- useage:
- disallow_status_code:
[]响应状态码过滤 - disallow_suffix:
[]后缀名过滤配置 - danger_fields:
[]危险操作字段过滤,例如注销,退出,删除等等的一些 API字段之类的
- disallow_status_code:
results_filter_config:
- des:Task 通道过滤配置
- useage:
- disallow_status_code:
[]响应状态码过滤 - disallow_suffix:
[]后缀名过滤配置 - danger_fields:
[]危险操作字段过滤,例如注销,退出,删除等等的一些 API字段之类的
- disallow_status_code:
deduplication_level
- des:去重等级:
0:LowLevel 只对页面敏感(url)1:MediumLevel 对页面和请求方式敏感(url + method)2:HighLevel 对页面、请求方式、参数名敏感(url + method + paramsName)3:SuperLevel 对页面,请求方式,参数名,参数值,POST提交数据敏感 (url + method + paramsName + paramsValue + POST)
- useage:
2
- des:去重等级:
logger_config
- desc:日志客制化配置
- useage:
- logger_level:配置日志输出等级,可选的日志等级有:
disable,info,warn,error,fatal,debug - logger_file_name:指定输出日志的文件名称,包含路径:
./log/HAWK-X_Crawler.log - logger_output_level:输出到日志文件的日志等级,配置的等级都会输出到日志文件中不会打印到屏幕:
[warn,info]warn,info等级的日志将会存储到日志文件中不会在屏幕中打印。 - logger_file_max_size:日志文件的大小,(单位:MB):
50 - logger_file_max_backups:日志文件备份的个数:
5 - logger_file_max_age:日志文件存在的天数:
5 - logger_prefix:日志前缀:
【HAWK-X】
- logger_level:配置日志输出等级,可选的日志等级有:
进阶使用
普通爬取
普通爬取是指非登录爬取,用于爬取非登录的网站。可以在终端命令行中,执行以下指令:
ez crawler -u https://www.target.com
登录爬取
登录爬取可谓是 HAWK-X 的一大特色,因为 HAWK-X 绝对是目前登录认证方式最全的网络安全爬虫工具/产品。
HAWK-X 支持:Cookie、Headers、LocalStorage、SessionStorage、可视化操作登录。而可视化操作登录又可分为:无头/非无头(本地/远程)。
分布式可视化操作登录将在 产品/工具联动 章节进行介绍。
Cookie/Headers 认证登录
在配置文件中的 headers 字段中进行配置:
headers:
- domain: '*'
headers:
cookie: csrftoken=808NwRQ5KX9hEnqFJ3UwISf8Z8FBorMuNLXXmcyCAlT11sBas5GRI3B9gRj7PFHO; sessionid=16xuhvusehujsm08km7ry7t3ibs32xi0; left_menustatue_NSFOCUSRSAS=0|0|https://xx.xx.xx.xx/task/task_entry/
Authorization: Bearer yJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
现在很多前后端分离站点使用 JWT 进行鉴权认证的的也可以配置,如上 Authorization。
PS:domain 字段为生效的域名,此处的配置一定要 遵从浏览器-->开发者工具-->应用程序-->Cookie 里面的 Domain 字段进行配置否则不容易登录成功:
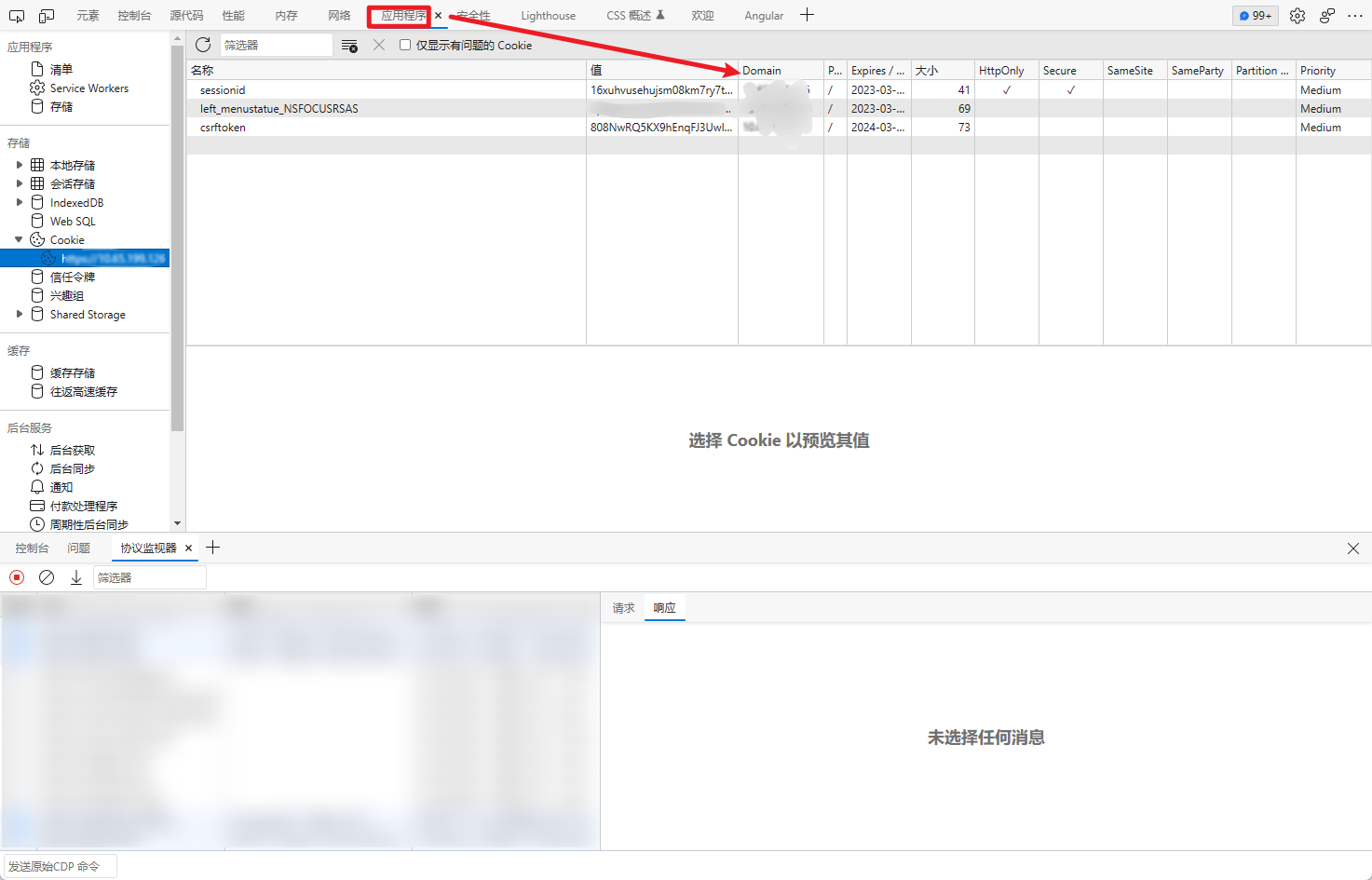
LocalStorage 认证登录
目前许多前后端分离站点,仅仅配置 headers、cookie 可能还会出现登录不成功的情况,那么这时就要考虑该站点在 LocalSorage 里面还塞了东西。这时你可以通过配置配置文件里的 local_storage 字段:
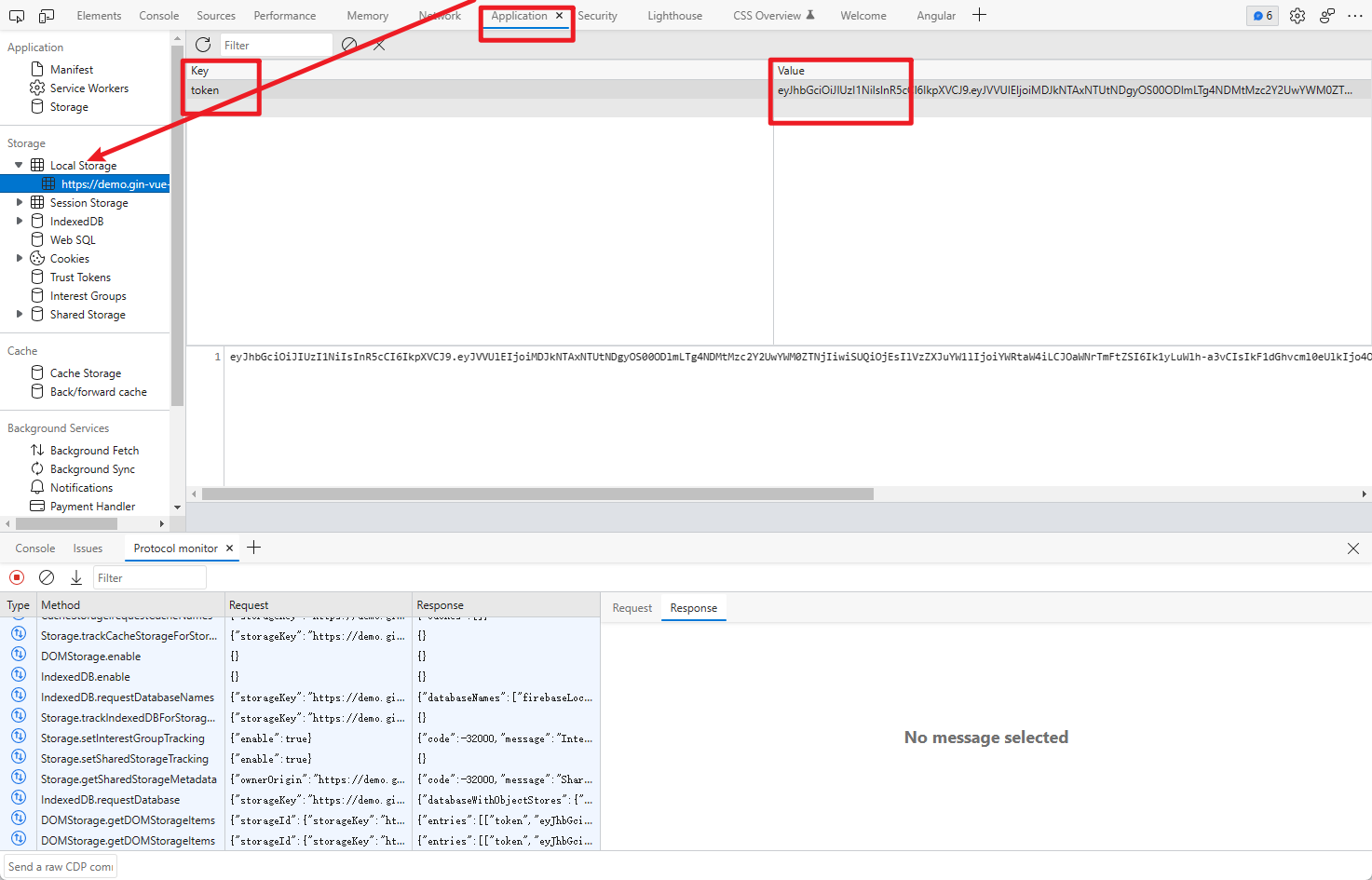
local_storage:
token: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJVVUlEIjoiMDJkNTAxNTUtNDgyOS00ODlmLTg4NDMtMzc2Y2UwYWM0ZTNjIiwiSUQiOjEsIlVzZXJuYW1lIjoiYWRtaW4iLCJOaWNrTmFtZSI6Ik1yLuWlh-a3vCIsIkF1dGhvcml0eUlkIjo4ODgsIkJ1ZmZlclRpbWUiOjg2NDAwLCJleHAiOjE2Nzg2MTQ5MzUsImlzcyI6InFtUGx1cyIsIm5iZiI6MTY3ODAwOTEzNX0.Q0SXBYEvjzfM__ZS4djiUF9rOipQiguil8Jmn2B-DNA
SessionStorage 认证登录
和 LocalStorage 类似,许多前后端分离站点也喜欢把一些和认证相关的信息存放在 SessionStorage 里面。两者的区别主要在于:SessionStorage 的生命周期为会话周期期间,会过期,而 LocalStorage 可以长时间存储。
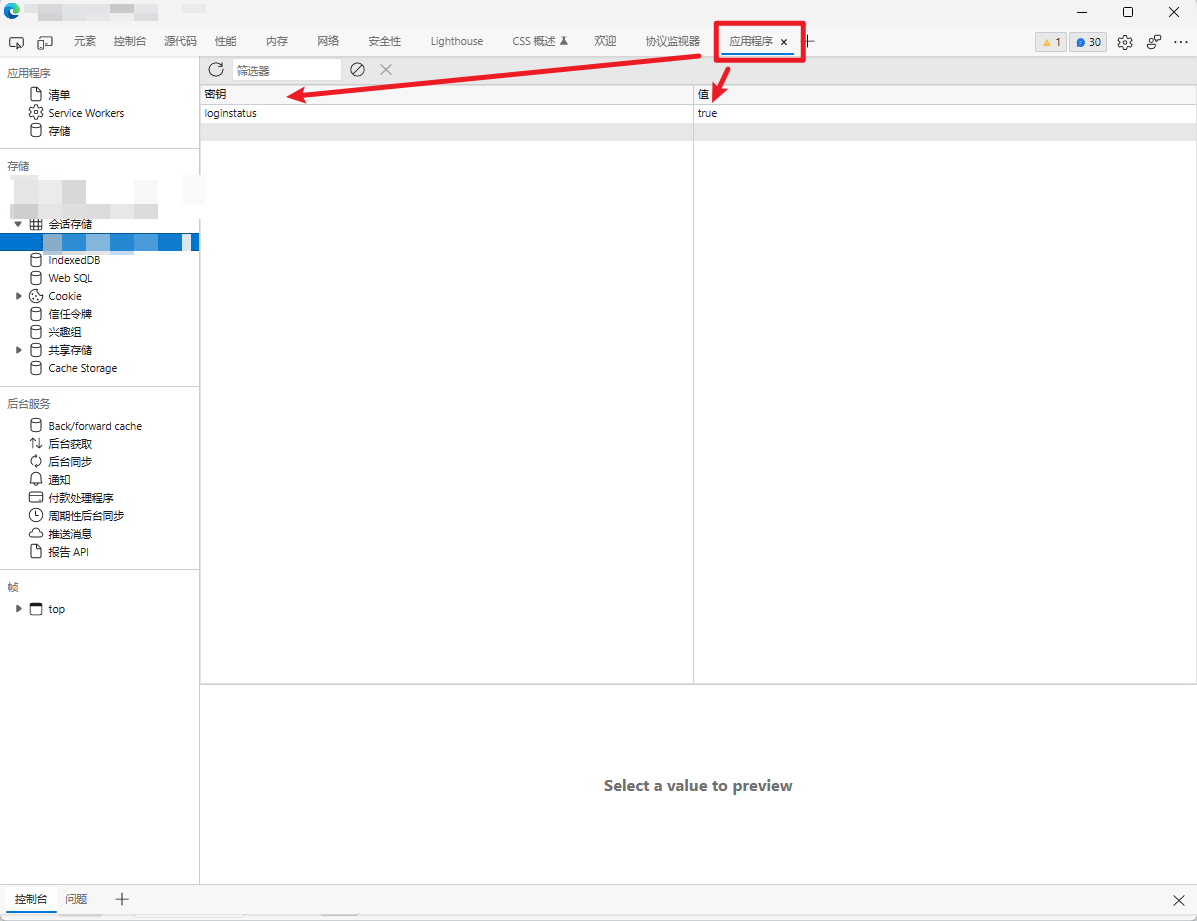
该站点就往 SessionStorage 写入了一个 loginstatus 字段用于判断是登录之类的。即使配置了 cookie 也是登录不成功的,所以也需要配置这个字段:
session_storage:
loginstatus: true
本地可视化非无头模式下手动操作认证登录
这个名字似乎看起来有些长有些绕,但是它绝对是体验最好的认证登录方式,因为使用它,不用在配置文件里配置任何东西,只需一个命令行参数--wait-login即可。
- 本地:相对的还有分布式服务器环境下的可视化操作登录方式
- 可视化/非无头模式:此功能必须牺牲掉无头模式,弹出一个浏览器窗口。如果不想牺牲,那么可以联动分布式插件 HAWK-Remote
- 手动操作:直接性的输入账号密码
确保登录成功之后,在命令行终端内按下回车键,即可继续爬取。还可以和分布式插件 HAWK-Remote 进行联动,在服务器环境下实现无头模式下进行远程可视化调用登录爬取。
useage:
ez crawler -u https://www.target.com --wait-login
PS:如果需要图形验证码验证,建议配置配置文件里的 disable_images: false 这样才会显示图片。
结果存储
如果想要保存爬取结果,那么可以通过以下 CLI 参数进行配置:
--text-output 输出简单的结果请求。例如:
[GET] https://example.comuseage:
ez crawler -u https://www.target.com --text-output ./result.txt
--json-output: 输出完整的请求 JSON 文件 。
content:
- Method:请求方式
- URL:请求地址
- Headers:请求头
- StatusCode:响应状态码
- Body:请求体,默认以 base64 编码的字符串
useage:
ez crawler -u https://www.target.com --json-output ./result.json
对抗反爬
在 HAWK-X V1.6 中突破了瑞数信息的反爬措施,其中内核已经内置了一些反爬对抗方法,如果遇到此类站点请你禁用掉配置文件中的 user_agent ,将其置空即可获得完整的反爬对抗能力。